

- ホーム > ブログ > 応用編 ―エンジニア向けブログ― >
2025年08月28日
画像認識ニューラルネットワークとは?
目次
エイシングのリサーチ&デベロップメント部でスペシャリストとしてAI開発案件の担当やTransformerモデルの構築とそれによる異常検知などに取り組んでいます。
その立場から、テックブログというかたちで技術を深掘りしてお伝えできればと考えています。
さて、今回の私の担当ブログではニューラルネットワークを用いた画像認識基礎について執筆していきたいと思います。ニューラルネットワークを用いた画像認識では主に畳み込みニューラルネットワーク(CNN)というモデルが使用され、初心者でも構築しやすく、かつ、画像以外のその他のタスクにも応用しやすいものとなっています。CNNモデルの構造・学習について学んだことがない方は、今回の内容で学んでその他のAI技術の習得にも繋げていっていただければと思います。
はじめに:ニューラルネットワークとは
ニューラルネットワークとは人間の脳の神経回路を模したモデルであり、ノードと呼ばれるもの同士が重みで結合した構造を取ります。図1の左に示している赤丸がノード、青線が結合重みです。破線で囲ったようなノードと重みの縦ひと纏まりをレイヤーと呼び、ニューラルネットワークはこのレイヤーを複数繋げていくことで構成されます。データの処理においては、図1のように最初のレイヤーにデータを入力し、入力したデータに重み行列(W)を掛けることで前のレイヤーから順に処理を行っていき、最終的に出力を得ます。
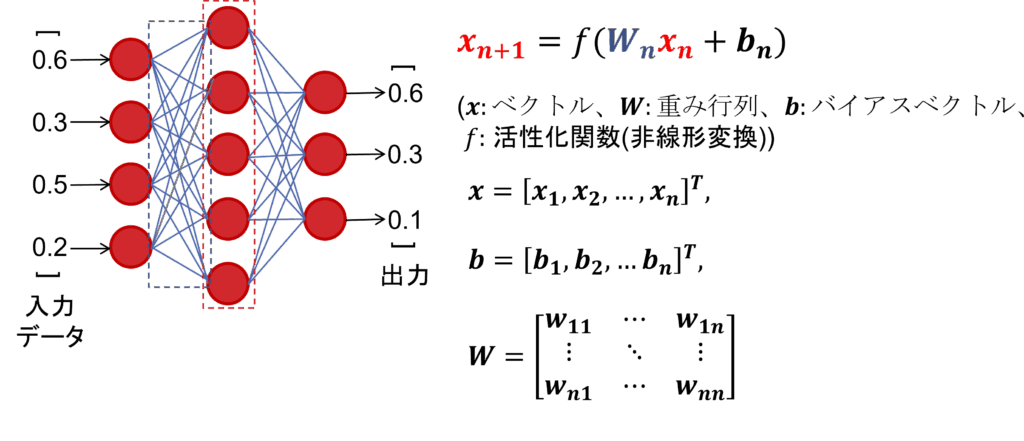
図1: ニューラルネットワーク(MLP)
MLPによる画像認識
まず最初に、マルチレイヤーパーセプトロン(MLP)について説明します。
MLPによる画像認識のイメージを図2に示します。

図2: MLPによる画像認識
MLPとは、最も単純な構造のニューラルネットワークモデルで、図1のようにすべてのレイヤーが全結合で構成されているニューラルネットワークです。このMLPの前半部分に特徴抽出用のレイヤーを結合したものがCNNとなります。MLPの入力データはベクトルの形式で入力され、重み行列との積計算と活性化関数の適用を複数回通して、最後のレイヤーでソフトマックス関数を適用して出力を得ます。具体的には以下の式で入力データ(x)を順に計算していき、出力を得ます。
$$
x_{n+1} = f(W_n x_n + b_n) (x:ベクトル、W:モデルの重み行列、b:バイアスベクトル、f:活性化関数)
$$
出力層のノードには入力データの分類クラスへの対応付けがされており、この出力ノードの確率値が最も高いクラスが入力データの分類先になります。ちなみに、この対応付けはモデルの設計者が決定するもので、図2では上から順に、「りんご」「みかん」「ばなな」としており、1つ目のノードの出力値が最も高いので入力画像は「りんご」であると判定されます。
ニューラルネットワークが入力に対して正しい出力を行えるようになるためには、モデルの「学習」と呼ばれる工程が必要であり、そちらについては後の項目で説明します。
活性化関数
活性化関数はベクトルを非線形変換するためのものであり、様々な種類がありますが、その中で最もよく使用されるのがReLU関数になります。ReLU関数は、負の値を0、正の値をそのまま出力する関数です。ReLU関数を使用しておけばモデルがある程度の性能を発揮できることが知られており、画像認識の場合、まずはReLU関数を使用しておくのが無難な選択になります。
ソフトマックス関数
ソフトマックス関数は出力を確率値に変換するための関数です。具体的には以下の式で計算されます。
$$
u_i = \frac{\exp(y_i)}{\sum_{j=1}^{d} \exp(y_j)}
$$
数式に\(exp()\)が含まれているのはモデルの学習時に微分計算を簡潔にするためです。
畳み込みニューラルネットワーク(CNN)
CNN構造の全体像
CNNは画像認識に特化したニューラルネットワーク構造であり、画像の持つ空間構造を活かして学習することができます。
CNNの簡易図を図3に示します。CNNは、MLPを「全結合層」として扱い、その前半部分のレイヤーに「畳み込み層」「プーリング層」などを組み合わせて構成されています。畳み込み層では画像の特徴の抽出、プーリング層では画像の特徴の圧縮を行い、最後に抽出された特徴を用いて全結合層で入力画像のクラスの推定を行います。CNNモデルでは、この畳み込み層とプーリング層を何層か繰り返した後、全結合層へと接続するのが一般的で、この繰り返しの特徴抽出構造によって、入力画像の局所的な特徴からグローバルな特徴まで段階的に学習することができます。
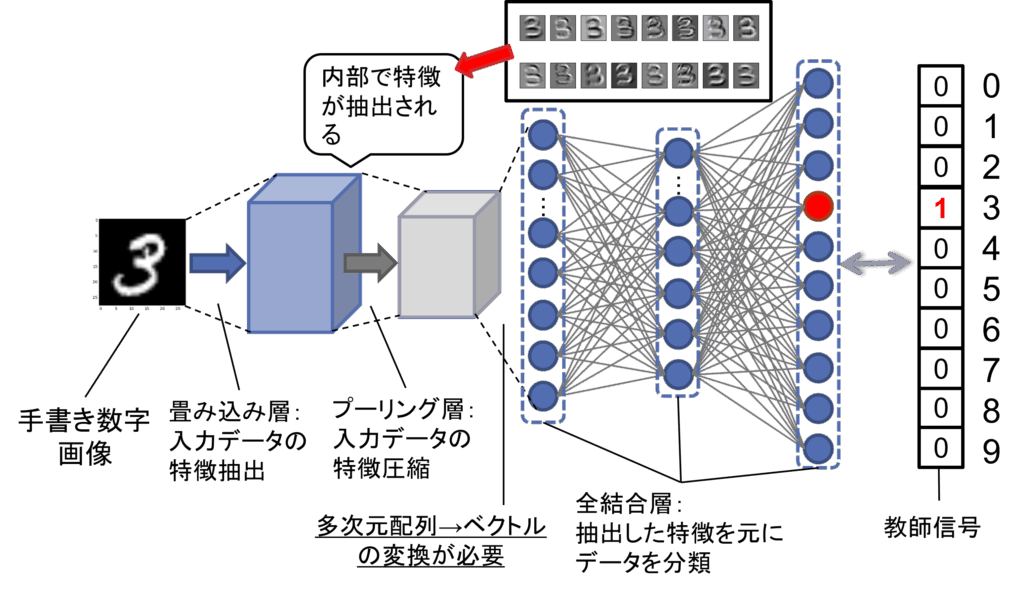
図3: 畳み込みニューラルネットワーク(CNN)
畳み込み層とフィルタ
畳み込みの構造を図4に示します。畳み込み層は、入力画像に対してフィルタ(カーネル)と呼ばれる小さな重み行列を滑らせながら局所的な特徴量を抽出する層です。例えば、3×3のフィルタを画像全体に適用し、縁や角、模様などのパターンを抽出します。この操作により、入力画像のの特徴を捉えた特徴マップ(特徴画像)が生成されることになります。
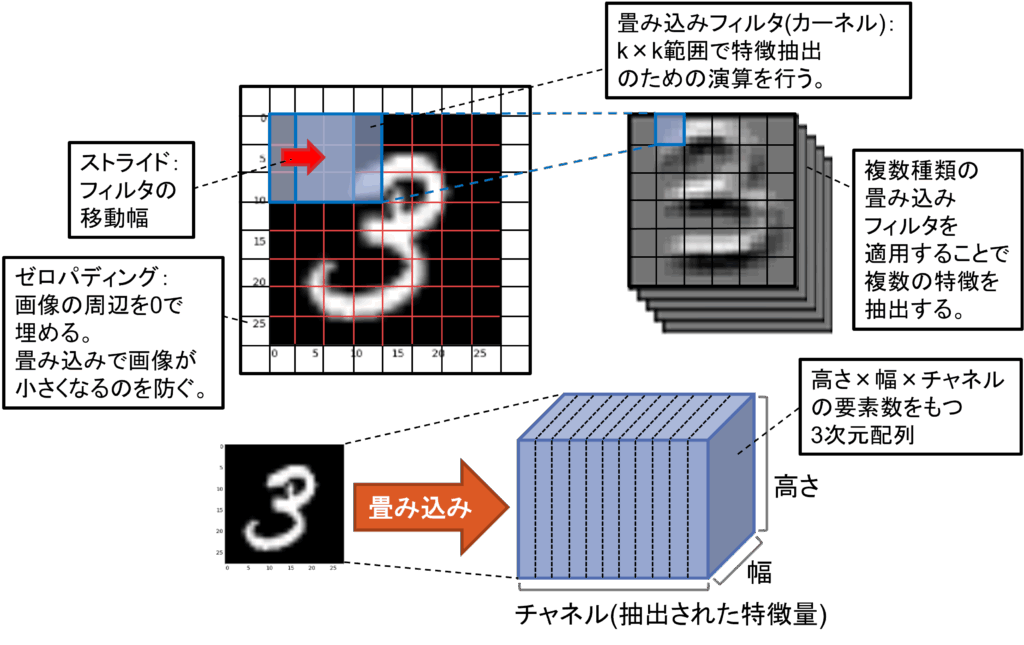
図4: 畳み込み処理
また、図5のように、一度の畳み込みにつき複数の異なるフィルタを使用することで、内部で複数の特徴マップが生成されることになり、これによって異なる種類の特徴を同時に捉えることが可能になります。図5の場合は1つ目の畳み込み処理で100枚のフィルタを適用しているため、モデル内部で100枚の特徴マップが生成されることになります。
この畳み込み層は数を重ねるほどモデルの推定精度が向上する傾向にあることが知られており、後述するResNet[1]というモデルでは152個のレイヤーを持つモデルが提案されています。
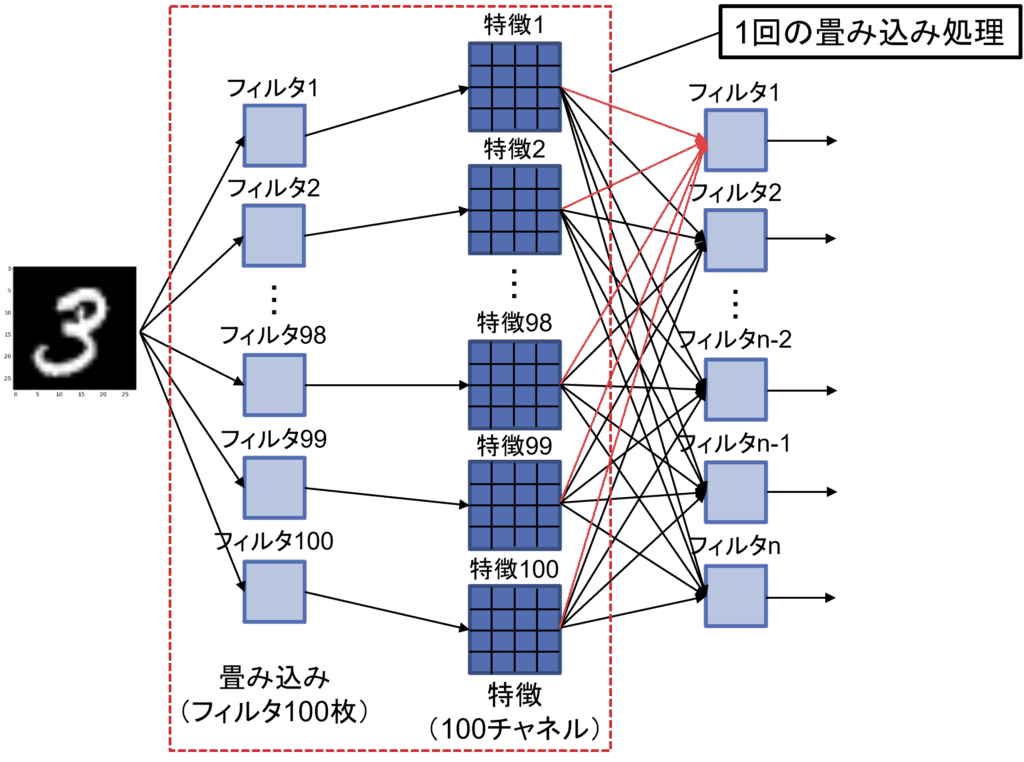
図5: 畳み込みフィルタ
プーリング層
プーリング層の構造を図6に示します。プーリング層は、特徴マップの空間サイズを縮小する役割を持ちます。代表的な手法には「最大値プーリング(Max Pooling)」や「平均プーリング(Average Pooling)」があります。指定範囲の領域の最大値や平均値を次のレイヤーへ出力するため、計算量が減少し、AIモデルが入力画像のズレに強くなる効果があります。
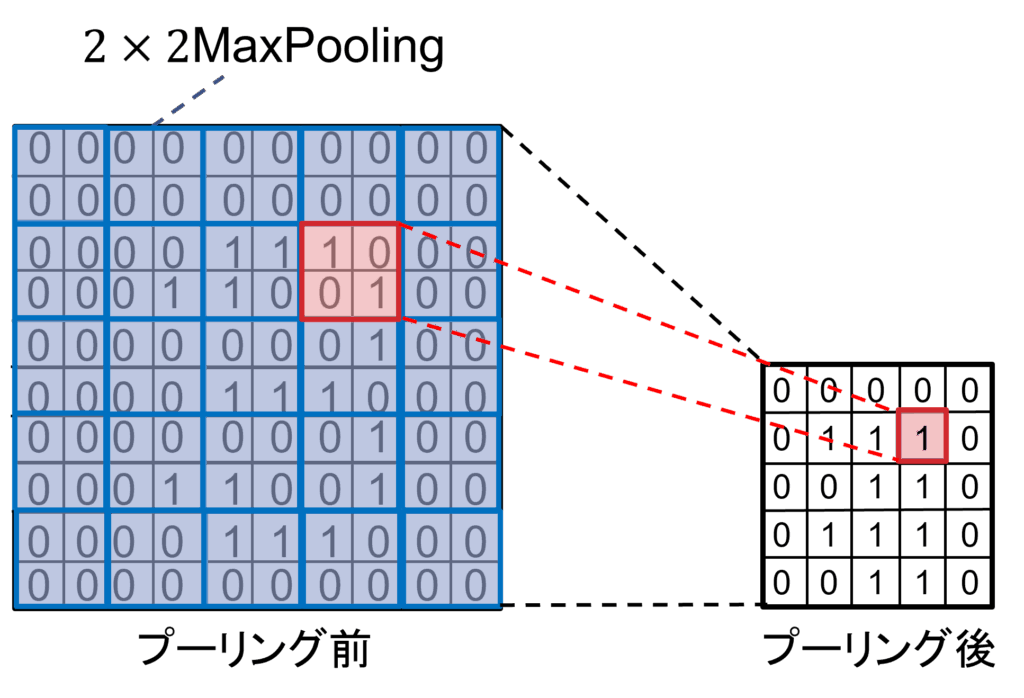
図:6: プーリング処理
モデルの学習と検証
ニューラルネットワークが入力に対して正しい出力を行うためには、学習と検証のサイクルが必要になります。学習とは、学習データを用いてモデルの重みを更新するプロセスであり、検証とは、未知のデータ(検証データ)に対するモデルの汎化性能を確認する工程です。モデルの学習は、「学習データのみ」を使用して繰り返し行い、学習に使用していない「検証データ」を用いて、モデルが未知のデータを分類できるかどうかの確認を行います。
損失関数
損失関数は、モデルの予測と正解との誤差を数値化する関数です。損失値は小さいほど、モデルの出力が正解に近いことを意味しています。ニューラルネットワークモデルは、この損失関数の値を最小にするようにモデルの重みパラメータを更新して学習を行います。画像分類においては、クロスエントロピー関数が一般的に使用され、以下の数式で記述されます。
$$
L=-\sum_{i=1}^d t_i \log y_i (t:教師信号, y:出力)
$$
tは教師信号と呼ばれるもので、入力データのクラスに対応する要素を1とし、他を0とするベクトルです。この表現方法をone-hot表現と呼びます。つまり、画像認識でクロスエントロピー関数を計算する場合は、正解クラスに対応する部分の出力ノードの\(log\)のみを計算することになります。
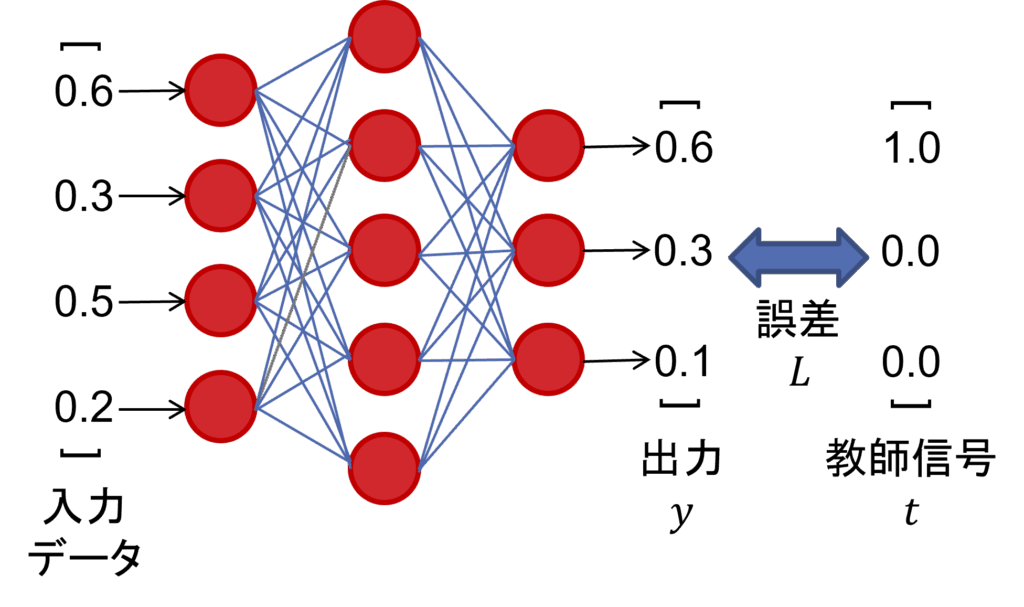
図7: モデル出力と損失
最適化アルゴリズム
損失関数の値を最小化するために、モデルの重みを勾配に従って更新します。勾配の計算には後述する誤差逆伝播法(バックプロパゲーション)が用いられ、重みの更新にはAdamやSGDなどの最適化アルゴリズムが使われます。この最適化アルゴリズムはこれまでの研究により多くの種類が考案されていますが、Adamを使用しておけば多くのタスクである程度良い結果を得られることが知られており、まずはAdamを使用してモデルの学習を試してみるのが無難な選択となります。
バックプロパゲーション
バックプロパゲーションは、モデルの出力から損失関数を通して各重みへと誤差を逆伝播させることで、各パラメータの勾配を計算する手法です。この手法では、合成関数微分を用いて図8のように損失関数の傾きを算出し、大域最適解をめざして各レイヤーの重みパラメータを勾配降下法によって繰り返し更新していきます。具体的な計算の工程は割愛しますが、これにより、モデルが出力と正解ラベル間の損失を元にパラメータを自己調整し、正しい出力ができるように学習が進みます。
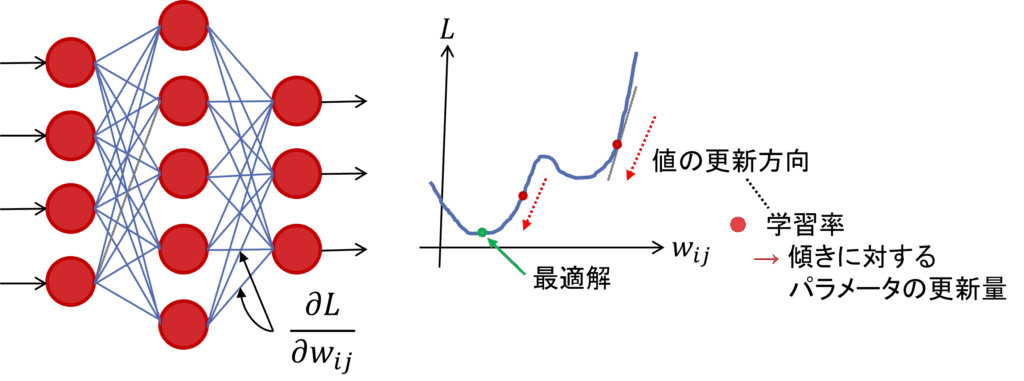
図8: 学習によるモデルパラメータの更新
過学習とその対策
過学習
モデルが学習データに過剰に適合してしまうと、未知データへの分類性能が低下する「過学習」が起こります。
実際に過学習を起こした場合のイメージを図9に示します。左が学習時の精度グラフ、中央が損失値のグラフであり、縦軸は推定精度と損失値、横軸は学習回数(epoch)、オレンジのグラフが学習データ、青のグラフが検証データです。この結果では学習データは高い精度で判別できていますが、精度と損失が検証データと大きく乖離しており、未知データの判別精度が低い状態となっています。原因のイメージ図としては図9の右の通りで、本来あるべきクラスの分離境界が青の破線であるとすると、モデルが学習データである赤色の点に過剰にフィッティングすることで赤色の破線を分離境界として学習してしまっているためです。
これを防ぐために、検証データでの評価を行いつつ、Dropoutレイヤーの導入やデータ拡張を適用します。
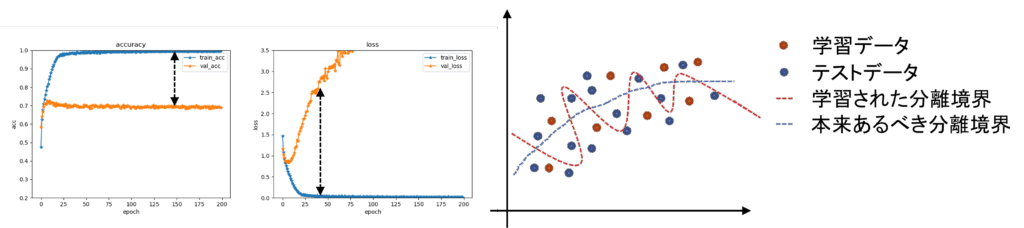
図9: 過学習
Dropout
Dropoutは指定した確率でモデル内のノードを削除する手法です。Dropoutの実行は学習時のみに行われ、削除されたノードの値は0として扱い、モデル内での計算が行われます。これは入力画像の一部を穴開きにして隠し、画像認識モデルから見えなくすることで、モデルによる画像の丸暗記を防ぐようなイメージです。これによってモデルの過学習を防ぎ、検証データの推定精度を上げることができます。
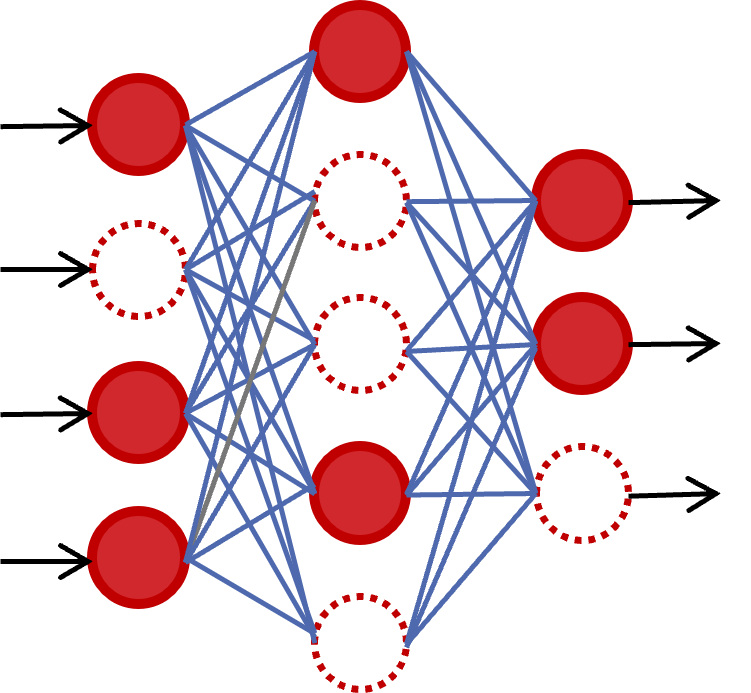
図10: Dropout
データ拡張
データ拡張(Data Augmentation)は、学習データを人工的に増やす手法であり、モデルの汎化性能向上に効果的です。特に画像認識においては、以下のような手法が一般的です。
- ランダム水平反転・回転
- 明るさ・コントラストの変更
- ランダム拡大縮小・平行移動
- ノイズの付加
これらの手法により、モデルは画像の変化に対して頑健になり、過学習のリスクも軽減されると共にモデルの推定精度向上の効果があります。
RandAugment
上記データ拡張の発展形として、RandAugmentというデータ拡張手法があります。RandAugmentはランダムで多様なデータ拡張を適用する手法で、画像データを取り出す度に、14種のデータ拡張からN個をランダムで選択し、Mの強度で適用します。
RandAugmentで選択される14種のデータ拡張の一覧は以下の通りです。
- ShearXY:シアー変換
- TranslateXY:平行移動
- Rotate:回転
- AutoContrast:コントラスト最大化
- Invert:色反転
- Equalize:ヒストグラム平坦化
- Solarize:ソラリゼーション(設定した輝度以上で画像をネガポジ反転)
- Posterize:ポスタリゼーション(減色処理)
- Contrast:コントラスト変換
- Color:カラーバランス調整
- Brightness:輝度変換
- Sharpness:シャープネス
- Cutout:正方領域のグレーマスク
- Sample Pairing:同バッチ内他画像との線形加算
RandAugmentでは、ランダムで選択するのはデータ拡張の種類のみで、データ拡張の強度は固定値(回転+30°と-30°等)で適用します。これはRandAugmentの原論文での検証の結果、強度を固定にする場合と強度をランダムにする場合で精度向上効果がほぼ変わらないことがわかっているためです。強度固定の場合でも高い推定精度向上効果を得ることができ、かつ、強度がランダムの場合と比較して学習が効率化されるため、固定強度が採用されています。
実際に使用されるCNNモデル例
VGG
VGG[2]は、オックスフォード大学のVisual Geometry Groupが提案したCNNモデルで、構造がシンプルながら高い性能を発揮することで知られています。CNNモデルの作成を行ったことがない方はまずはこのVGGを参考にモデルを作成してみることをお勧めします。
原論文で提案されているVGGのモデル構造を図11、VGGの推定精度(ImageNetデータセットによる検証)を図12に示します。VGGは深さが異なるVGG-11, VGG-16, VGG-19などのバリエーションがあり、これらの図から畳み込みを重ねるほどモデルの推定精度が向上していくことがわかります。
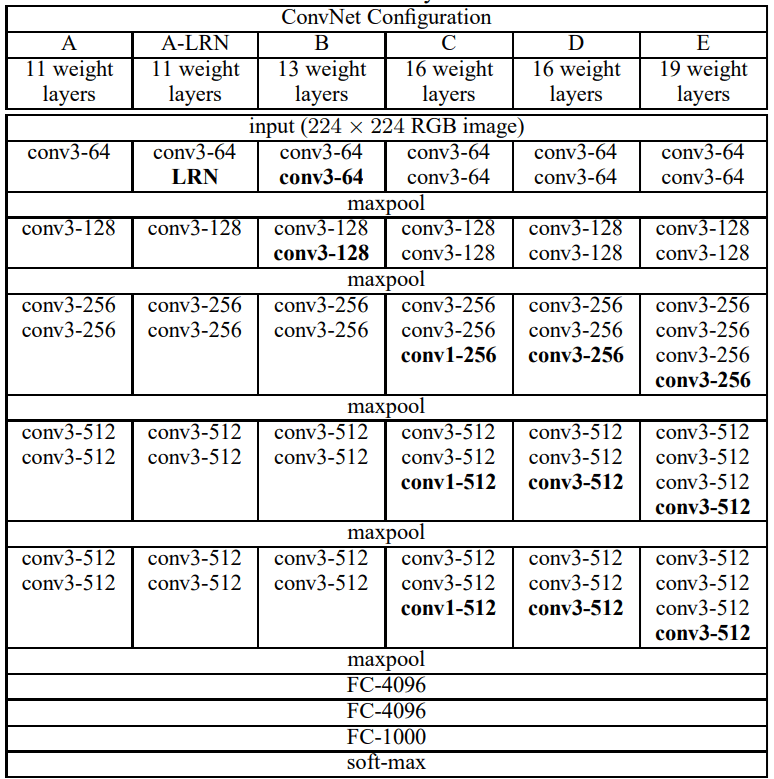
図11: VGGモデル構造(原論文より)
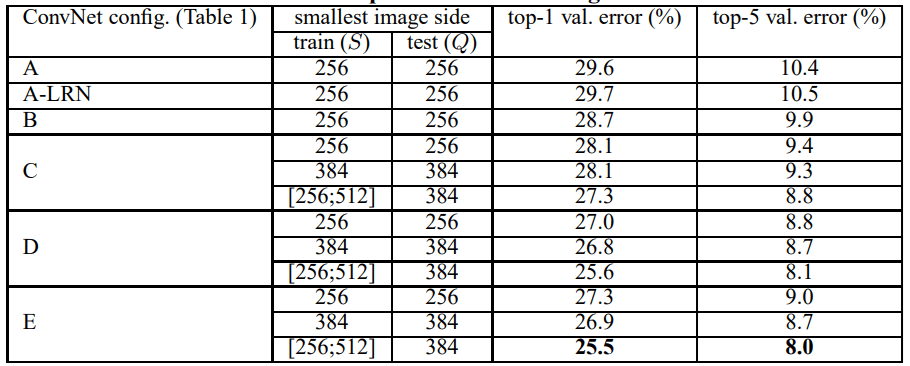
図12: VGG推定精度(原論文より)
ResNet
ResNet[1]は、マイクロソフトの研究者らによって提案されたモデルで、非常に深いネットワークでも学習が可能なように工夫されています。単純な構造で高い精度を発揮することができ、画像認識でよく使用されるモデルの1つとなっています。
ResNetの最大の特徴は、図13に示すような残差ブロックと呼ばれる構造を導入していることです。ニューラルネットワークにはレイヤー数を増やしすぎると学習が上手く進まなくなる勾配消失と呼ばれる問題があったのですが、ResNetは「入力信号をスキップ接続として後段に渡す」ことで、勾配消失問題を回避し、深いネットワークでも安定して学習できるようにしています。実際の計算式は非常に単純であり、以下のように一部のレイヤーをスキップして先のレイヤーに足し合わせるだけです。
$$
y = F(x) + x
$$
ここで\(F(x)\)は複数の畳み込み処理を行うブロック、(x)はスキップ接続される入力です。この仕組みにより、ResNetは100個以上のレイヤーを重ねても学習が可能となり、VGGを超える非常に高い精度で画像を認識することができるようになりました。
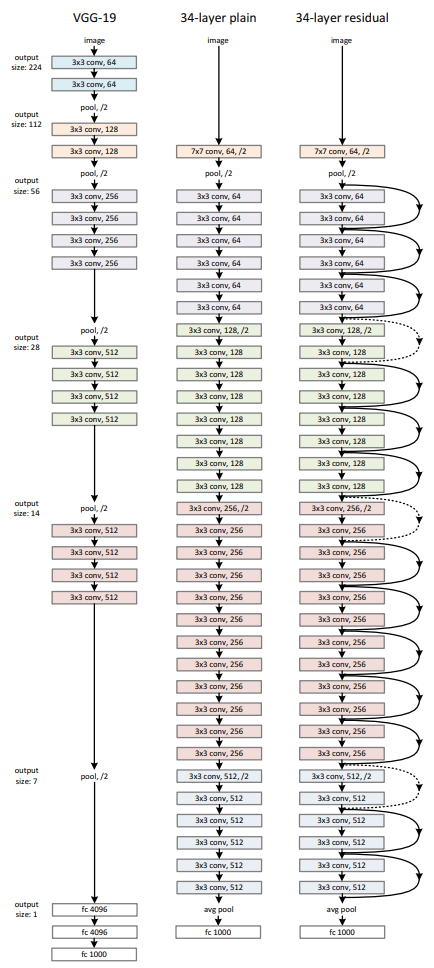
図13: ResNet残差ブロック(原論文より)
まとめ
いかがだったでしょうか。このように、ニューラルネットワークを使用した画像認識では非常に単純な構造ながら高い精度で画像を認識することができます。プログラミング言語PythonのフレームワークであるPytorch、Tensorflow、Keras等を利用することで簡単に自分のオリジナルの構造を持つCNNモデルを作成したり、既存の学習済みモデルを読み込んで使用することができるので、より深く理解するするためにもぜひ触ってみることをお勧めします。
次回の私の研究ブログでは低解像度の画像を綺麗に拡大する技術「超解像」について執筆していきたいと思います。
執筆者:平田大貴(ソリューション開発部)
参考文献
[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun,
“Deep Residual Learning for Image Recognition,”
arXiv:1512.03385, Dec. 2015.
[2] Karen Simonyan and Andrew Zisserman, “VERY DEEP
CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION,”
arXiv:1409.1556, Apr. 2015.